Integration Testing
Integration Testing is a web development terminology used to test the software modules. Software is subdivided into multiple modules that different web developers code. These web developers vary in expertise, experience, and subject specialization.
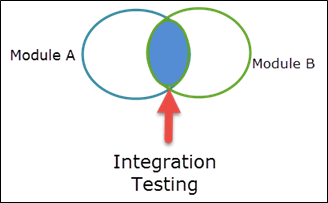
What is Integration Testing?
Integration Testing is a web development terminology used to test the software modules. Software is subdivided into multiple modules that different web developers code. These web developers vary in expertise, experience, and subject specialization. When modules are separately developed, integration testing helps to check any potential deficiencies. Integration testing paves the way for system testing.
 Source: Guru99.com - What is System Integration Testing (SIT) with Example
Source: Guru99.com - What is System Integration Testing (SIT) with Example
Terms Used For Integration Testing
- Integration and Testing (I & T)
- String Testing
- Thread Testing
Types of Integration Testing
Big Bang Integration Testing
Each component of the software or application is tested together. For example, if an application has four different modules, then all these are tested concurrently.
Top to Down Integration Testing
All the components are tested from top to bottom with a control flow and architectural hierarchy.
Bottom to Top Integration Testing
In bottom-to-top integration, the components can be developed and tested simultaneously. The last component is established and tested at the same time.
Incremental Integration Testing
Stubs and drivers are developed and used in incremental integration testing. All programmers are added one by one, and then testing is carried out.
Sandwich Integration Testing
It is also named hybrid or mixed integration testing. Sandwich integration testing is a combination of bottom-up and top-down integration testing methods. A three-layer testing approach is applied in this testing.
Black Box Testing
Powerful software and applications are examined by using the black box technique. It is essential to inspect each element of the software accurately. The integration team can perform the software/app testing with the help of black-box testing. In this way, the team tests the links, buttons and scrolls through the user interface. They usually don't need to mess with the coding or back end.
Difference Between Unit Testing and Integration Testing
Unit Testing
Unit testing is the first which is performed in the Software Testing Life Cycle. Unit testing is performed by the specific developer who is responsible for a dedicated component or module development. Unit testing was done to check the functionality of the unit code.
Integration Testing
Integration testing is teamwork. All the separately developed modules are integrated and tested at the same time. This testing is done before system testing. The prime objective of integration testing to check any potential flaws or problems in the software/app modules after the integration.
System Testing and Integration Testing
Integration testing consists of two or more modules of a software or application, while system testing is complete software testing before final submission.
Why Might You Want Integration Testing?
Integration is the second phase of testing combinations of different software components and their interaction. The prime objective of I & T is to find out the flaws and defects by integrating various components.
For example, You are interacting with an E-Commerce app. You wish to buy your favorite T-shirt. Then you find it out through the products and add to the cart. Now you have to pay the required amount with an integrated payment gateway. You get a purchase message like Thanks for purchasing with us. This is a sequence of actions controlled by different modules. Integration testing performs checks of components to keep them integrated and functional.
What are Stubs and Drivers?
Dummy software programs are required to accomplish the testing activity.
A stub is generally the software called by the module under testing, while Driver is the software that calls or responds to the module in integration testing.
These temporary software act as substitutes for the missing models. Which are not in the development program but necessary for module functioning. Just the data simulation occurs while calling from the under-test module.
Why is the Integration Testing Plan Mandatory?
The integration testing plan carries approaches and methods of integration testing. It is clear for the testing team to assume their roles and responsibilities. Prerequisites of integration testing are must to address before execution. It also aids in establishing a healthy testing environment. The integration testing plan also illustrates the risks and the mitigation.
Problems Integration Testing Helps to Solve
- Integration testing enables the simultaneous testing of different modules.
- All the modules are tested and rectified before going for system testing.
- Integration testing does not demand the completion of the whole software/application.
- It paves the way towards successful project completion and submission.
How to Implement the Integration Testing
Integration depends upon the teams and scenarios in a DevOps environment. The testing team may consist of designers, developers, testers, or any other members assigned by the management.
A software project is typically divided into three parts.
- Planning
- Execution/Coding
- Validation
Integration testing falls under the validation category. Its primary objective is to check the segments of a module. The linking, connection, and communication between the components is the principal target of this testing.
Sequence of Testing
- Unit Testing
- Integration Testing
- System Testing
- Acceptance Testing
Implementation of integration testing is done through the following steps.
Planning
There are two types of planning for integration testing.
- Project Planning
- Individual Planning
Project Planning
Once the client submits his project requirements, the management team analyzes them thoroughly. The management also decides which types of testing are to be carried during the project progress. However, it is dependent on the project, team, and the situation.
Individual Planning
If the management adds the integration testing in the project outline, then individual planning is implemented. It includes the following.
- Tools to be used
- Time of execution
- Resources
- Team
- The objective of testing
Execution
After the completion of the plan testing team executes the integration testing. All the team members perform their part to implement the integration testing plan successfully.
Execution of integration testing follows.
- Tests to be performed
- Results obtained
- Defects during implementation
Data Log and Analysis
The team logs all the data during execution. It helps in analyzing the errors and performance during the integration of the modules.
Defects Rectification and Retesting
The responsible individuals rectify the potential defects faced during integration testing. Then the testing team retests modules and all infected components for successful integration.
Best Practices of Integration Testing
- Prepare the test plan for the required testing.
- Set up the test cases and scripts
- Execution of test cases and evaluation of defects data
- Data tracking, addressing the defects and retesting.
- Keep this going till the successful integration of all modules.
- Settle the testing strategy and test data before execution
- Critical components and modules require more attention. Highlight the key fields to focus on and then execute testing.
- Interface design verification, database, external hardware, and software application are the core-centered testing areas.
- Test data is vital to sort out the faults. Data examination is also essential.
- Execute the integration after the unit testing. It helps to avoid any complexity during the integration testing.
- It is better to log your activity or progress. This helps in identifying failure reasons and ways to address them.
- A testing plan is beneficial for the testing team, and the project manager addresses things in a sequence.
Common Pitfalls of Integration Testing
- Database, platform, and environment badly affects the integration testing.
- There are many changes followed by integration testing for the best client experience.
- Integration of two components developed by two different developers is a big challenge. People with different mindsets and approaches design a component, and its synchronization is not a piece of cake.
Resources for Integration Testing
Numerous resources and tools help the testing team to execute their testing plans. Below are some of the most used tools.
Rational Integration Tester
RIT (Rational Integration Tester) tool eliminates the bugs in integration testing.
- It furnishes a scripting-free environment with a reduction of failure risks.
- RIT helps in creating code-free and reusable stubs.
- It overcomes the development and test cycle time during the early stages of the testing.
Protractor
Protractor is E2E testing an open-source automation framework.
- It is favored for Angular and AngularJS based applications.
- Its WebdriverJS applies particular drivers and a native browser for application interaction validity.
- Protractor is mainly designed for integration testing and to run the instances of the applications.
- It encompasses the user's point of view while conducting tests.
- It also aids in writing end-to-end test suites.
Citrus
Citrus is a java written test framework. It is used in the integration testing of message-based EAI applications.
- Citrus renders robust validation mechanisms for XML message contents.
- It also permits building complex testing logic.
- It supports sending and receiving messages, error simulation, message timeout simulation, variable definitions, automatic retries, and database validation, with many other features.
- Citrus is a low-cost and open-source testing solution.
Tessy
Tessy helps in identifying the application's code coverage. This software testing tool assists in executing integration and unit testing of embedded software.
- Tessy's CTE(Classification Tree Editor) serves teams in specifying the test cases.
- Tessy supports C and C++ programming languages.
- It helps in providing code coverage and generating the test reports of tests carried.
- Tessy includes Test Interface Editor, Test Data Editor, and Workspace.
- It helps analyze the interface and determine the used variable.
Was the article helpful?
Want to write for DXKB?
Feel free to contribute. People from DXKB community will be more than happy.

Prokop Simek
CEO
Related articles
ALL ARTICLES
Code Coverage
Code Coverage measures the percentage of source code lines that are covered by automated tests. If you have 90% CC, it means that 10% of the source code is not being tested at the moment.
Read moreSmoke Testing
It is a test aimed to verify that the most important features of the product really work. This term was used during testing hardware and the product passed the test when it did not burn or smoke.
Read moreStaged Rollout
A staged Rollout enables you to release the upcoming product version slowly in a gradual way. You can slowly increase the percentage of users who receive the update.
Read moreTest Cards
Test cards help you to test and validate your business ideas by defining how you will test them, what you will measure, and what success looks like.
Read morePenetration Testing
Penetration Tests are performed to identify network security weaknesses. It is a "friendly cyberattack" for spotting flaws and potential vulnerabilities.
Read moreALL ARTICLES
Contribution
We are happy you want to contribute to DXKB. Please choose your preferred way