Apache Kafka
Apache Kafka is an open-source event streaming platform created by LinkedIn in 2011 which initially served as a messaging queue.
What Is a Apache Kafka
Apache Kafka is used as a high-available messaging queue. It receives messages from other services in the environment and provides it to the others.
Kafka is commonly deployed as a cluster with 3 or more brokers (nodes) to have data replicas (backups) on other brokers. Kafka receives messages from producers and provides them to consumers. Each message is saved to a topic that has a name. The message can be a text, number or an object, depending on the implementation. The topic is a category name for messages. Producers write messages to topics and consumers read messages from topics. Kafka retains all messages for a specific time and consumers are responsible to track location of these messages. Kafka topics are divided into a number of partitions, which contains messages in an unchangeable sequence. Partition is a section that is separated from other segments and enables users to divide data into logical sections. Each message in a partition has a specific offset.
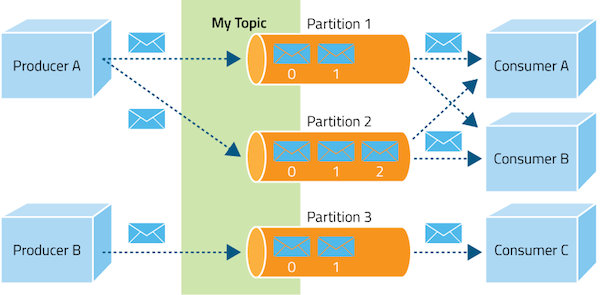 Source: Apache Kafka
Source: Apache Kafka
Kafka uses Zookeeper as a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. When new brokers are added to the cluster, ZooKeeper will start utilizing them by creating topics and partitions.
Why You Might Want to Implement Apache Kafka
Kafka helps you to move large amounts of data in a reliable way and is a very flexible tool for communication between services. It's possible to scale Kafka easily and it ensures that data are read just once.
Advantages of Kafka:
- High-Throughput
- Fault-Tolerant
- Durability
- High Concurrency
- Real-time Handling
- Scalability
- Low Latency
- By Default Persistent
Problems the Apache Kafka Helps to Solve
Microservices architecture without Kafka
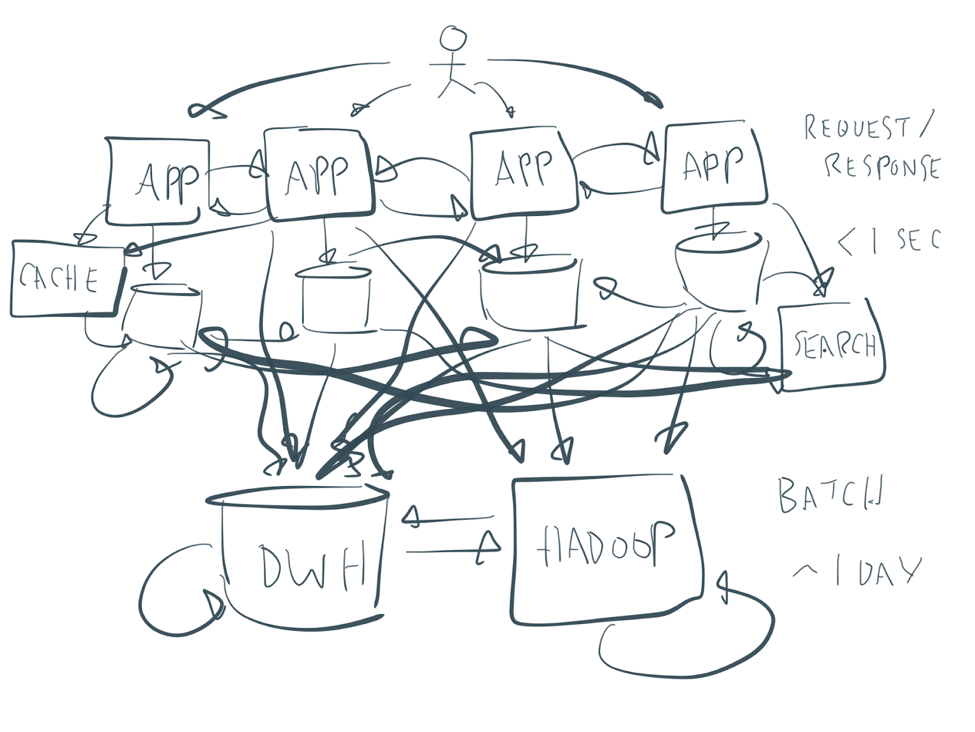 Source: Confluent: Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies?
Source: Confluent: Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies?
Microservices architecture with Kafka
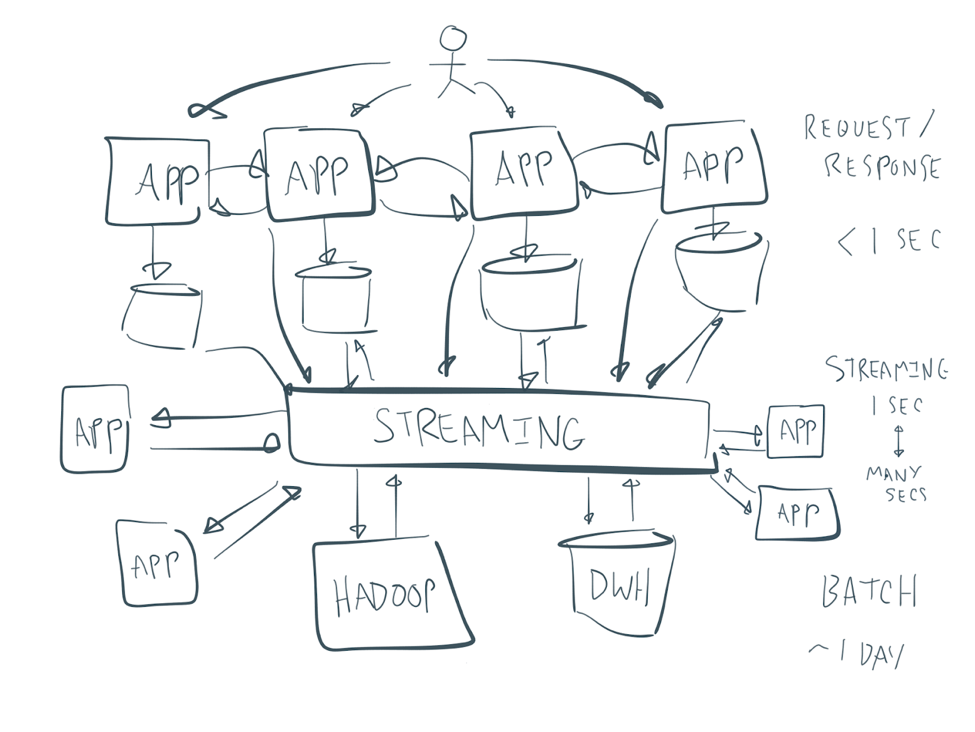 Source: Confluent: Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies?
Source: Confluent: Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies?
How to Implement Apache Kafka
It's necessary to have deployed an Apache Kafka cluster including Zookeeper clues to manage Kafka nodes. There are several libraries for programming languages to connect Kafka easily.
- Kafka.js for JavaScript
- Java Client
- C++ Client
- Python Client
- Go Client
- .NET Client
- JMS Client
Common Pitfalls of the Apache Kafka
- Keeping too much data
- Old Data in Topics Not Being Deleted
- Not balancing topics
- Not accounting for long-term storage
- No disaster recovery
- No API enforcement
Resources for the Apache Kafka
- cloudkarafka.com: Apache Kafka for beginners - What is Apache Kafka?
- kafka.apache.org: Apache Kafka Quickstart
- Confluent.io: Introduction to Kafka
- Confluent.io: Kafka Clients
- thenewstack.io: Apache Kafka: A Primer
- softwaremill.com: Message queue benchmark
- 5 Pitfalls to Kafka Architecture Implementation
- data-flair.training: Advantages and Disadvantages of Kafka
- NewRelic.com: 20 Best Practices for Working With Apache Kafka at Scale
Was the article helpful?
Want to write for DXKB?
Feel free to contribute. People from DXKB community will be more than happy.

Prokop Simek
CEO
Related articles
ALL ARTICLES
Continuous Delivery
Practicing Continuous Delivery means that you adopt practices to be ready to release product changes any time you want. Your product is always ready to deploy to production.
Read moreContinuous Integration
Continuous Integration is a software development practice that makes developers integrate code changes into a shared repository routinely and frequently. Usually, each person integrates at least daily and that ensures them that their code changes do not break anything.
Read moreDevops
DevOps is a set of practices that brings development and operations teams together. The collaboration helps to release software much faster.
Read moreAutomated Deployment
An Automated Deployment allows an application to be deployed across various stages of the development process. It minimizes the need for manual intervention.
Read moreDocker Compose
Docker Compose simplifies the configuration and management of multi-container Docker applications using a YAML file.
Read moreALL ARTICLES
Contribution
We are happy you want to contribute to DXKB. Please choose your preferred way